Im Detail
In vielen Einsatzgebieten von bildverarbeitenden Lösungen sind KI-Systeme mittlerweile Standard. KI bezieht sich in diesem Fall auf Machine Learning (ML), einem Unterbereich von KI. Besonders in der Bildverarbeitung sind ML-Verfahren inzwischen gängig und halten immer mehr Einzug in die Industrie.
Oftmals besteht das Problem, dass diese ML-Systeme datenhungrig sind und neue Daten den Systemen »gezeigt« werden müssen, um die Probleme der Unternehmen effektiv lösen zu können. Wenn ein Unternehmen derzeit beispielsweise neue oder andere Objekte mithilfe von ML erkennen möchte, müssen Daten aufwändig generiert und manuell von Menschen vorverarbeitet werden. Anschließend trainieren ML-Experten die Modelle nach, bevor sie wieder einsatzbereit sind. Dieser Prozess ist sehr zeitintensiv und kann insbesondere für kleine und mittelständische Unternehmen, die häufig ein sich stetig änderndes Produktportfolio oder geringe Losgrößen haben, den Einsatz der neuesten ML-Verfahren erschweren.
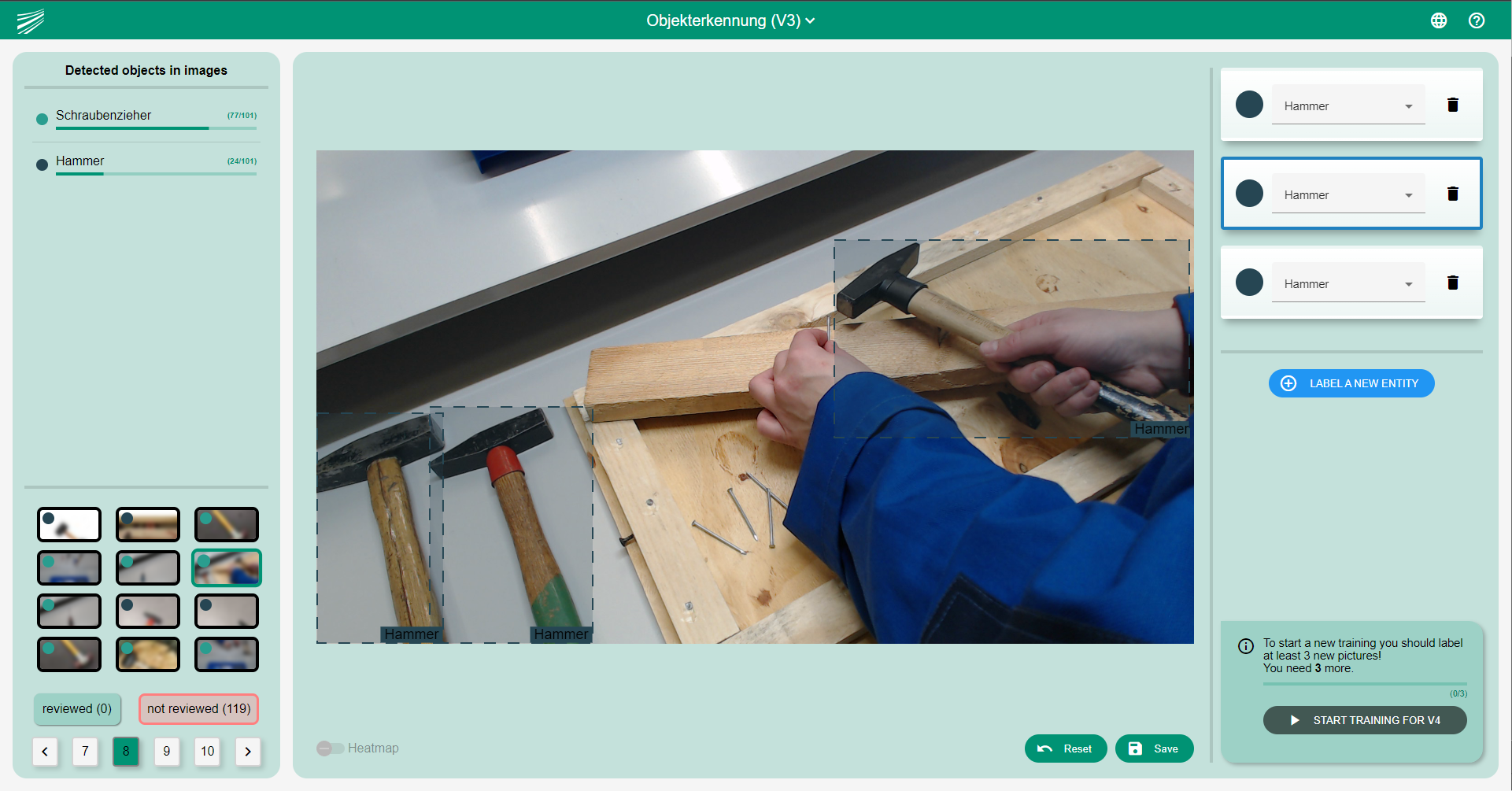
Mithilfe von interaktivem Maschinellem Lernen für Bildverarbeitungslösungen haben Unternehmen die Möglichkeit, ihre Daten und die stetige Veränderung und Verbesserung der ML-Modelle selbst zu kontrollieren. Hierfür wurde eine WebApp entwickelt, die es ermöglicht, die aktuellen Daten einzuspeisen. Ein Prozessexperte innerhalb des Unternehmens kann die Daten sichten und für das ML-Verfahren vorbereiten. Die intuitive Oberfläche zeigt bereits, wie gut das aktuelle Modell die Objekte erkennt. Zusätzlich kann eine Heatmap generiert werden, die den Fokus der KI auf dem aktuellen Bild zeigt und Aufschluss darüber gibt, worauf sich der Objektdetektor konzentriert. Dieses Verfahren ermöglicht es Menschen, die undurchsichtige Berechnung des Modells besser nachvollziehen zu können.
Es wird ersichtlich, welche Objekte und Klassen davon nicht so gut erkannt werden. Gezielt werden Bilder, bei denen sich das Modell am unsichersten ist, als Priorität in der Auswahlleiste angezeigt. Die Bounding Boxen und die Klassen der Objekte können dann einfach verändert und abgespeichert werden. Eine weitere Übersicht der erkannten Klassen gibt bereits Aufschluss darüber, ob das ML-Modell bestimmte Klassen bereits gut erkennt oder nicht. Es erlaubt den Nutzern der Anwendung ein Verständnis, wie gut das aktuelle Modell bereits Objekte erkennen kann. Diese Objekte können ebenfalls gezielt vom Anwender vorverarbeitet werden. Es wurde darauf geachtet, dass nicht große Mengen an Daten von Menschen vorverarbeitet werden müssen, sondern, dass wenige Daten bereits ausreichen, um inkrementelle Verbesserungen herbeizuführen.
Bei dieser Vorverarbeitung werden Experten des Unternehmens einbezogen, da sie ihre Werkstücke und relevanten Objekte am besten kennen und verstehen. Sie sind somit die geeignetsten Personen, um der KI die Objekte beizubringen. Zudem muss die Datenvorverarbeitung nicht an Dritte weitergegeben werden und bleibt somit innerhalb des eigenen Unternehmens.
Das Herzstück dieser Anwendung ist jedoch nicht nur die Vorverarbeitung der Daten, sondern das Nachtraining, das von den Experten des Unternehmens vor Ort angestoßen werden kann. Anschließend kann eine neue Version des Modells eigenständig untersucht und Verbesserungen in der Erkennung ermittelt werden. Zur Optimierung des Modells können weitere Daten eingespeist und erneut nachtrainiert werden. Dieser Prozess wird so oft wiederholt, bis ein zufriedenstellendes Ergebnis erzielt wurde. Die schrittweise Verbesserung des Modells ermöglicht es den Mitarbeitenden vor Ort, ihre Ziele mithilfe von ML zu erreichen und ihr Verständnis dafür zu erhöhen.
Dies kann die Akzeptanz und das Wissen über KI stärken und Widerstände gegenüber KI abbauen. Das schrittweise Nachtrainieren sorgt zudem dafür, dass nur notwendige Daten vorverarbeitet werden und das Nachtraining der Modelle ressourcenschonender ist, insbesondere auf kleineren Datensätzen. Dies ist oft besonders relevant für kleinere Unternehmen, aber auch für Unternehmen, die sich energieeffizienter mit dem Thema KI auseinandersetzen möchten.
Die Anwendung ermöglicht ebenfalls kleinen Unternehmen, in das Maschinelle Lernen der Bildverarbeitung einzusteigen und ihre eigenen Probleme mithilfe von KI zu definieren und zu lösen.
 Fraunhofer-Institut für Produktionstechnik und Automatisierung IPA
Fraunhofer-Institut für Produktionstechnik und Automatisierung IPA